Der ultimative LLM Proxy: Modelle sofort wechseln mit Synaplan
Die KI-Landschaft entwickelt sich in rasantem Tempo. Wöchentlich erscheinen neue Modelle, Preisstrukturen ändern sich ohne Vorwarnung, und API-Ausfälle können Ihre gesamte Anwendung lahmlegen. Die eigene Infrastruktur an einen einzigen Anbieter zu binden, ist längst nicht mehr nur eine technische Altlast – es ist ein Geschäftsrisiko.
Die Lösung: Ein LLM Proxy.
Ein LLM Proxy (oft auch AI Gateway genannt) fungiert als zentrale Steuerungsebene zwischen Ihren Anwendungen und den verschiedenen KI-Modellen auf dem Markt. Anstatt anbieterspezifische SDKs fest in Ihren Code zu integrieren, kommunizieren Ihre Anwendungen mit dem Proxy. Der Proxy übernimmt dann das Routing, die Protokollierung und die Verwaltung der Anfragen an die zugrunde liegenden Anbieter.
Synaplan wird mit einem leistungsstarken, integrierten LLM Proxy ausgeliefert, der Ihnen die volle Kontrolle über Ihre KI-Infrastruktur gibt.
Warum Sie einen LLM Proxy brauchen
Wenn Sie sich direkt mit einem KI-Anbieter wie OpenAI oder Anthropic verbinden, erben Sie dessen Einschränkungen. Fällt deren API aus, fällt auch Ihre App aus. Erhöhen sie die Preise, steigen Ihre Kosten. Veröffentlicht ein Wettbewerber ein schnelleres, günstigeres Modell, müssen Sie Ihren Integrationscode umschreiben, um es nutzen zu können.
Ein LLM Proxy abstrahiert diese Komplexität. Er bietet einen einzigen, standardisierten API-Endpunkt für Ihre Anwendungen und kümmert sich im Hintergrund um die lästigen Details wie anbieterspezifische Formatierungen, Authentifizierung und Fehlerbehandlung.
Modelle sofort per Konfiguration wechseln
Mit dem LLM Proxy von Synaplan ist der Wechsel von Modellen keine Entwickleraufgabe mehr, sondern eine einfache Konfigurationsänderung.
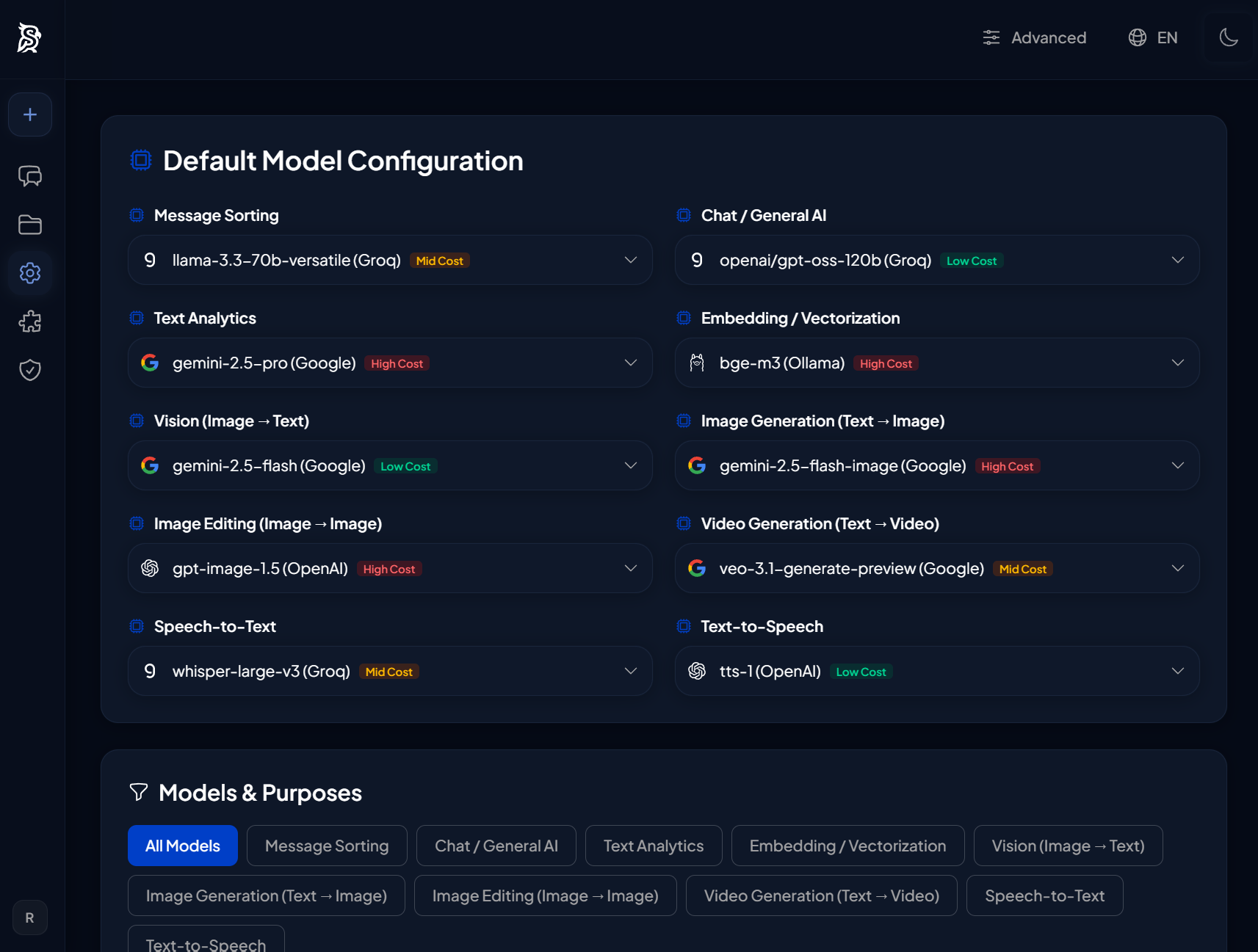
Über die Synaplan-Administrationsoberfläche können Sie problemlos mehrere KI-Anbieter konfigurieren – seien es Cloud-APIs wie OpenAI, Google Gemini, Anthropic, Groq und Mistral oder lokale Modelle, die über Ollama laufen.
Sie können spezifische Anwendungsfälle bestimmten Modellen zuordnen. Zum Beispiel:
- Komplexe Denkaufgaben können an ein großes Modell wie GPT-4o oder Claude 3.5 Sonnet weitergeleitet werden.
- Schnelle Aufgaben mit hohem Volumen (wie Zusammenfassungen oder Datenextraktion) können an ein günstigeres, schnelleres Modell wie Llama 3 oder Mistral geroutet werden.
- Verarbeitung hochsensibler Daten kann exklusiv an selbst gehostete, lokale Modelle geleitet werden.
All dies geschieht, ohne dass Sie auch nur eine einzige Zeile Code in Ihren Frontend-Anwendungen oder Chat-Widgets ändern müssen.
Automatisches Routing und Fallbacks
Ein robuster LLM Proxy ermöglicht nicht nur den manuellen Modellwechsel, sondern geht auch automatisch mit Ausfällen um.
Wenn Ihr primärer KI-Anbieter einen Ausfall hat oder Ihre Anfragen drosselt (Rate Limiting), kann der Synaplan LLM Proxy automatisch auf einen Backup-Anbieter ausweichen. So wird sichergestellt, dass Ihre Nutzer niemals eine Fehlermeldung sehen, nur weil eine Drittanbieter-API einen schlechten Tag hat.
Sie können Fallback-Ketten konfigurieren: Wenn Anbieter A ausfällt, versuche Anbieter B, und wenn das fehlschlägt, weiche auf ein lokales Modell aus. Dies garantiert maximale Verfügbarkeit und Zuverlässigkeit für Ihre KI-Funktionen.
Zentrales Audit-Logging und Kostenkontrolle
Wenn verschiedene Teams in Ihrem Unternehmen unterschiedliche KI-Modelle nutzen, wird die Nachverfolgung von Nutzung und Kosten schnell zum Albtraum.
Ein LLM Proxy löst dieses Problem, indem er den gesamten Datenverkehr zentralisiert. Jeder Prompt, jede Antwort und jedes Token wird an einem Ort protokolliert. Synaplan bietet vollständige Audit-Trails, mit denen Sie genau sehen können, wer welche Modelle nutzt, welche Daten gesendet werden und wie viel das kostet.
Sie können Rate Limits festlegen, Budgets pro Team durchsetzen und die Einhaltung von Datenschutzrichtlinien sicherstellen – alles über ein einziges Dashboard.
Machen Sie Ihre KI-Strategie zukunftssicher
Das beste KI-Modell von heute ist vielleicht nicht das beste von morgen. Durch die Implementierung eines LLM Proxys mit Synaplan entkoppeln Sie Ihre Anwendungen von den zugrunde liegenden KI-Anbietern.
Sie gewinnen die Flexibilität, neue Modelle am Tag ihrer Veröffentlichung zu übernehmen, die Zuverlässigkeit automatischer Fallbacks und die Sicherheit zentraler Protokollierung. Hören Sie auf, Ihre Integrationen ständig neu zu schreiben, und fangen Sie an, Ihre KI-Infrastruktur wie ein Profi zu verwalten.